RAGにおけるRetriverの性能評価に関して
Tech Blog
2024/11/7
はじめに
株式会社iDEAKITTのCTOのNです。iDEAKITTでは、運営しているSaaS上でアンケートテンプレートを提供しており、このテンプレートを用いて簡単に最初のアンケートを作成することができます。一方で、これらのテンプレートは約700種類提供されており、その検索性が課題となっていました。無論、全文検索などの従来型の検索で間に合う部分もあると思いますが、よりユーザーの意図したニュアンスにマッチするテンプレート検索ができるという意味で、RAGによる検索を試してみることにしました。ただし、RAGの精度の大部分はRetriverの検索精度に依存することもあり、Retriverをどのように実装し、どう評価するかがユーザーの満足度に関わってきそうです。したがって、今回はRetriverの実装と性能評価に関する部分に焦点を当て、iDEAKITTでのユースケースにおける実験のレポートを記事としてまとめたいと思います。
RAGシステムの性能評価
RAGシステムは大きく分けて、検索モジュールと生成モジュールから構成されますが、それぞれの評価手法は異なります。本稿は、検索モジュール、つまりRetriverに関する性能評価のみを扱い、RAGシステム全体の評価には言及しません。ただし、RAG全体の評価フレームワークで2つほど興味深いものがあったので、簡単に紹介いたします。これらは、次回以降の記事で利用するかもしれません。
まず、RAGの包括的な性能評価手法として、論文の引用数が多いものにRAGAS[1]がありました。RAGASは、Faithfulness, Answer relevance, Context relevanceという3つのメトリクスを用いて、検索モジュールと生成モジュールを区別せずに、生成されたテキストを統合的に評価します。その他に、AWS AIもRAGChecker[3]という手法を提案しており、こちらは検索モジュールと生成モジュールを個別に評価するためのメトリクスを提供しています。
Retriverの性能評価
生成モジュール側はハルシネーションやコンテキストの関連性などを調べるより複雑な指標を用いますが、検索モジュール側では情報検索(IR)システム分野で用いられる古典的な評価指標を用いることが一般的なようです。本項では、情報検索システムの評価指標のうち, Recall@K, Precision@K, NDCG@Kを概説します。これらの指標は、実験の評価セクションで利用するものとなります。
Recall@K
Recallと聞くと馴染み深いのは、分類モデルの評価指標で、次のものが思い浮かびます。

上式TP, TNは混同行列におけるTrue Positive(TP), False Negative(FN)で、「正例だけど負例として判定してしまった = FN」が0のときにRecallは1となります。つまり、すべての正例のうち、正しく正例と予測できた割合を表す指標です。
一方で、Recall@Kは次式で表されます。

Recall@KのKは、検索上位K件のKを表しています。つまり、検索結果の上位K件の中に、関連するアイテムが含まれている割合を測定しています。例えば、Recall@5 = 3/10のように書けば、関連があると期待される文書(これをRとします)が10件あり、文書全体に対する検索結果の上位5件の中に、Rに含まれる文書が3件あったことを表します。今回の場合は、アイテム = アンケートテンプレートで、全ての関連するアンケートテンプレートの集合をTとすれば、分母は|T|となります。
Recall@Kの式自体は非常にシンプルなものですが、結果がテストデータの作りに大きく依存してくるので、検索クエリに対する関連文書の選定次第、つまり作業者による検索精度のボラティリティが大きくなりそうです。テストデータの大部分は人力チェックになると思いますが、検索クエリの意図に沿う関連文書の選定を数人で行い、バイアスを低減する努力が求められるでしょう。
Precision@K
Recall@KがあるようにPrecisionに対する@Kもあります。通常のPrecisionは、分母のFN部が、False Positive(FP)となり、以下で表せます。

Precisionの場合は、「正例と判定されたうち、本来は負例であったもの = FN」が0の場合に1となります。
一方で、Precision@Kは次のように表されます。

この場合、文書全体に対する検索結果上位K件のうち、関連文書が何件あったかを測定することになります。Recall@K、Precision@Kがあるので、これらの調和平均であるF1スコアに関する@Kを、 2 * (Precision@K * Recall@K)/(Precision@K + Recall@K) で計算可能です。
アンケートを、ラクに速く。
タナカさんなら、AIがアンケートの設計から分析まで一気通貫で対応。数日かかっていた作業が数分で完了し、すぐ施策に活かせます。
無料ではじめられるので、まずはお試しください。
Normalized Discounted Cumulative Gain (NDCG@K)
NDCG@Kは、検索結果やレコメンデーション結果の上位K件の "順序" の適切さを評価する指標です。数理的には、DCG@KをIDCG@Kで割って正規化することで得られます。つまり、DCGが0から1に正規化された値がNDCGとなります。

DCG, IDCGは歴史的に複数の定義があるようですが、一般的なWeb検索企業が利用しているとされる以下のものを用います[7]。

DCGの指数部にある rel_i は 検索結果のi 番目のアイテムの関連度スコアを表します。DCGでは上位アイテムの関連性スコアにより大きな重みを付与し、下位に行くほど1/log₂(i)で割り引きます。一方で、IDCGは理想的な順序、つまり検索結果の関連性スコアを高い順に並べ替えた時のDCGであり、達成可能な最大のスコアとなります。したがって、rel_π(i)は検索結果の関連性スコアを高い順に並べ替えた時のi番目のスコアとなります。
例えば、検索結果の関連度スコアが[2, 0, 1, 3, 0]であった場合、rel = [2, 0, 1, 3, 0], rel_π = [3, 2, 1, 0, 0]となります。rel_πは理想的にはこのような順序で検索結果が出力されてほしいという並びになっていますね。この理想と現実の検索結果にどれほどギャップがあるかをNDCGで定量化することができます。
実験で用いるRetriver
情報検索システムの性能評価に関する事前知識を紹介したので、次に本稿で利用する具体的なRetriverを決定していきます。
iDEAKITTでは、AWSを利用しているため、AWS内の技術スタックでRAGを完結させるには、Bedrockを用いるのがベストプラクティスであるようです。Bedrockにおける検索モジュールにはAmazon Kendraという高機能な文書検索システムを使うのが推奨されています。ただし、単なるプレーンテキストであるアンケートテンプレートを検索するにはハイスペックすぎるため、より純粋なベクトルDB+類似度検索で文書検索を行うことにします。また、情報検索システムでは検索された文書の順位も性能に関わる重要な要素であるため、検索結果に対するRerankingも行います。
ベクトルDBと埋込み
ベクトルDBの選択肢は複数ありますが、データセットがそれほど大規模なものでもないため、qdrantを利用します。qdrantはOSSで提供されているRust製のベクトルDBで、自前でホストできるのが特徴です。さらに、ローカルでの永続化やインメモリでも利用できるため、SQLite的な使い方ができます。ローカルでの永続化ではSQLiteのDBファイルとしてデータが書き出され、ファイル全体で10MBほどでした。10MBであれば、全データがメモリに乗り切るため、アプリケーションと同一のコンテナ内で利用することもできるかもしれません(パフォーマンスは未検証です。)また、インメモリで利用する場合は、gensimのword2vecを利用したことのある人であれば、かなり近い使い心地です。qdrant以外の有力な選択肢にはクラウドで提供されているpineconeもあります。
ベクトルDBが決定したら、次は埋め込みをどうするかです。これは直感的には決定できないので、
AWSが提供するamazon.titan-embed-text-v1
OpenAIのtext-embedding-3-small
の3つの埋め込みを用いて、これらの中で検索性能がより良いものを用いることにします。特に, SentenceTransformerはFargateやEC2のCPUでも動作するため、大きなトラフィックが見込まれないアンケートテンプレート検索では最も低コストに運用できそうです。
Reranking
RerankingにはCross Encoder[4][5]というニューラルネットワークベースのアーキテクチャを用います。以下は, sbert.net からの引用です。
First, it is important to understand the difference between Bi- and Cross-Encoder.
Bi-Encoders produce for a given sentence a sentence embedding. We pass to a BERT independently the sentences A and B, which result in the sentence embeddings u and v. These sentence embedding can then be compared using cosine similarity:
In contrast, for a Cross-Encoder, we pass both sentences simultaneously to the Transformer network. It produces then an output value between 0 and 1 indicating the similarity of the input sentence pair:
A Cross-Encoder does not produce a sentence embedding. Also, we are not able to pass individual sentences to a Cross-Encoder.
As detailed in our paper, Cross-Encoder achieve better performances than Bi-Encoders. However, for many application they are not practical as they do not produce embeddings we could e.g. index or efficiently compare using cosine similarity.
Cite: https://sbert.net/examples/applications/cross-encoder/README.html
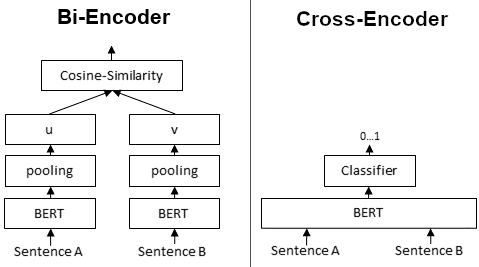
つまり、文書検索システムにおいて、Cross Encoderは、クエリと全ての関連文書(図では、Sentence A, Bとなっている)を同時に入力し、Attention層で類似度計算を直接実行するモデルとなります。そのため、高精度ではあるものの毎回モデル内部で埋め込みを取得する必要があり、Bi Encoderに比べ計算効率が悪いようです。(Bi Encoderでは埋め込みが既に取得できていれば、ベクトル間の類似度計算をするだけです。)
そのため、大規模な計算にはBi Encoderが向いているとされていますが、今回は検索結果上位10件のみを対象に、Cross Encoderを用いることにします。
アンケートを、ラクに速く。
タナカさんなら、AIがアンケートの設計から分析まで一気通貫で対応。数日かかっていた作業が数分で完了し、すぐ施策に活かせます。
無料ではじめられるので、まずはお試しください。
Retriverのコンポーネント
次の構成のRetriverを実装し、実験を行います。このとき、Embeddingでは, 前述する3つ(Titan, OpenAI, SentenceTransformer)を用います。そのため、埋め込み毎に個別にRetriverが提供されます。

実験
実験の目的
アンケートテンプレートのRetriverにおいて、埋め込みの違いよる検索性能を評価すること
Retriverの準備
qdrantに aws, open-ai, sentence-transformerという3つのコレクションを作り、それぞれに対応する埋め込みでアンケートテンプレートベクトルを取得し、qdrantに保存しておきます。
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
client = QdrantClient(":memory:")
client.create_collection(
collection_name="aws",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
client.create_collection(
collection_name="open-ai",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
# SentenceTransformerのみ次数が異なる
client.create_collection(
collection_name="sentence-transformer",
vectors_config=VectorParams(size=768, distance=Distance.COSINE),
)アンケートテンプレートの一例(MD形式)
# アンケート概要
* ID: 01G7XP6QXQWXAMKGTJYSPBFGBN
* アンケート名: サイトの認知経路・訪問目的を調査するための設問
* アンケート説明: サイトの認知経路・訪問目的を調査するための設問
* カテゴリ: ユーザーを深く理解する
* タグ:
# アンケート内容
* Q.1: どのように当サイトを知りましたか?
* 設問タイプ: 単一選択
* 選択肢1: インターネット検索
* 選択肢2: Facebook
* 選択肢3: Twitter
* 選択肢4: Instagram
* 選択肢5: メールマガジン
* 選択肢6: 知人からの紹介
* 選択肢7: その他
* Q.2: サイトに訪問してた目的を下記より全てお選びください
* 設問タイプ: 複数選択
* 選択肢1: 目的A
* 選択肢2: 目的B
* 選択肢3: 目的C
* 選択肢4: 目的D
* 選択肢5: その他qdrantへの文書の挿入
point = PointStruct(
id=ULID("01G7XP6QXQWXAMKGTJYSPBFGBN").to_uuid(),
# アンケート文書のベクトル
vector=[0.72, -0.53, -0.22, .....],
# metadata
payload={"title": "サイトの認知経路・訪問目的を調査するための設問", ...}
)
client.upsert(
collection_name=collection_name,
points=[point]
)評価データセット
今回は、Notebook LMと協調し、筆者一人で以下の構造のデータセットを作成しました。このようなデータ構造が合計13個あります。(実験なので、かなり小規模なデータセットです。)
queryは検索のためのクエリで、relevant_documentsには関連性が最も高いであろうと考えられる順序で並んだ文書IDがリストされます。したがって、当該queryを入力に、qdrantから文書を検索し、relevant_documentsの順序どおりに該当する文書が検索できるほど、その埋め込みは検索性能が良好であると評価します。
[
{
"query": "顧客満足度の調査", // queryはユーザーの検索クエリ
// relevant_documentsは、クエリに関連する文書のID
// 配列の先頭側に位置するほどより関連度が高い
"relevant_documents": [
"01HSARPS31FQX13ZQ82VFJFG5K",
"01HA6MZ46ZJ8PFKWB822FATS3A",
"01HAP1MSFAT4WHQXF18P31X8JE",
"01HRZFYA1734YT7CQ3HMHC8SFG",
"01J70MHMJ9YFPNPM8JK49KC53H",
"01HSAR6ZDYAYGJ4608W3XTNC0A",
"01HS7EN4TVTNWC7H47K0MAPT9Z",
"01HAP3AYXV73N5C7RCVM6HFFAB",
"01HS7ZGH2TY1V1R5SRYPZP8K9M",
"01G6SHVDF6DW740MB7C849JCJ4"
]
}
]評価
評価方法
評価データにある13件のクエリを3つのRetriverに入力し、検索結果と評価データの relevant_documentsを用いて、各Retriverに関するPrecision@K, Recall@K, NDCG@Kを計算し、それらを比較します。Recall@K, Precision@Kの計算には次のコードを用います。
def recall(actual, predicted, k):
act_set = set(actual)
pred_set = set(predicted[:k])
result = round(len(act_set & pred_set) / float(len(act_set)), 2)
return result
def precision(actual, predicted, k):
act_set = set(actual)
pred_set = set(predicted[:k])
result = round(len(act_set & pred_set) / float(k), 2)
return resultNDCG@Kには[6]の実装を用いました。NDCGでは、relをどのように決定するかという議題が残されていますが。本実験では評価データの上位に位置する文書ほど高い関連性を持つことにし、最大値をrelevant_documentsの長さの整数値、最小値を1として、relevant_documentsの上位からその整数値を割り振ります。つまり、
"relevant_documents": [
"01HSARPS31FQX13ZQ82VFJFG5K" // => 関連スコア10
"01HA6MZ46ZJ8PFKWB822FATS3A" // => 関連スコア9
"01HAP1MSFAT4WHQXF18P31X8JE" // => 関連スコア8
"01HRZFYA1734YT7CQ3HMHC8SFG" // => 関連スコア7
"01J70MHMJ9YFPNPM8JK49KC53H" // => 関連スコア6
"01HSAR6ZDYAYGJ4608W3XTNC0A" // => 関連スコア5
"01HS7EN4TVTNWC7H47K0MAPT9Z" // => 関連スコア4
"01HAP3AYXV73N5C7RCVM6HFFAB" // => 関連スコア3
"01HS7ZGH2TY1V1R5SRYPZP8K9M" // => 関連スコア2
"01G6SHVDF6DW740MB7C849JCJ4" // => 関連スコア1
]のように関連度スコアが割り振られます。そして、検索結果と評価データセットのマッチングを行い、評価データセット内に検索結果の文書がある場合、当該関連スコアをそのまま用います。そうでない場合は、関連スコアは0とします。
この関連スコアの取得アルゴリズムをPythonで実装したものが以下となります。
relevant_docs = [
(10, "01HSARPS31FQX13ZQ82VFJFG5K"),
(9, "01HA6MZ46ZJ8PFKWB822FATS3A"),
...,
(1, "01G6SHVDF6DW740MB7C849JCJ4"),
]
def relevant_score(searched_document_id: str, relevant_docs: \
List[Tuple[int, str]]) -> int:
for score, document_id in relevant_docs:
if document_id == searched_document_id:
return score
return 0
relevant_score("01HA6MZ46ZJ8PFKWB822FATS3A", relevant_docs)# => 9
relevant_score("foobar", relevant_docs) # => 0結果
各指標
以下は, 3つの埋込による検索性能の比較表です。テーブルの各行は、13個(indexは0から開始)のクエリに対応するPrecision, Recall, NDCGです。例えば、第0番目の結果に着目すると、Recall、Precisionともに最も高いのはAWS、NDCGはOpenAI, SentenceTransformerが同値で最も高いとなります。

それぞれの埋め込みに関する各指標をplotしたものが次のグラフです。概形だけを見ると、Open AIとSentenceTransformerが似たような形になっています。

各指標の基本統計量
生の結果だけを眺めても傾向が見えづらいので、結果表の基本統計量を確認します。

count: データの標本数
mean: データの平均
std: データの標準偏差
min, max: データの最小、最大値
n%: そのパーセンタイル数での値を示しており、データのn%がこの値より下に、(100-n)%が上に分布していることを表す。例えば、25% = 0.3は、データポイントの25%が0.3以下で、75%が0.3を超えていることを示す。50%はちょうど中央値に該当する。
結果の考察
Recall, Precision, NDCGのmeanおよび50%に位置する値(中央値)に着目すると、全ての項目でOpen AIが最も高い値となっていることが分かります。minに着目すると、最もminが大きいのもOpenAIです。maxも言わずもがなですね。一方で、AWS Titan vs SentenceTransformerでは、mean, 50%ともに概ねSentenceTransformerのほうが性能が良好であることも読み取れます。
目視ではOpen AIが優れていそうに見えましたが、次は統計的な仮説検定を用いて、それぞれの評価指標に有意差があるかを確認します。サンプルサイズが13という小標本のため正規性の仮定が難しいので、Exact法によるWilcoxonの符号順位検定を用いることにします。scipyでは、 stats.wilcoxon(x, y, mode='exact')のようにmode='exact'を指定することで正規近似ではなく、Exact法でp値を計算するようです。
結果としては、下記のようなコードで全ての組み合わせに関するwilcoxon検定を実施しましたが、有意水準5%でいずれも優位な差となるものはありませんでした。
from scipy.stats import wilcoxon
wilcoxon(aws_score["recall"], openai_score["recall"], mode='exact')
wilcoxon(aws_score["precision"], openai_score["precision"], mode='exact')
wilcoxon(aws_score["ndcg"], openai_score["ndcg"], mode='exact')最も統計検定量Wが小さくなるものは, Open AIとSentenceTransformer間のprecisionで、W=7.5で、p値=0.271でした。したがって、今回の実験においては、3つの埋め込み間には統計的に大きな性能差が見られないという結論となりました。ただし、mean, medianはOpen AIが大きいので、この性能差をうまく定量化できるように、多様で十分なサイズの評価データセットを構築して再度評価を行う必要があるでしょう。
おわりに
まずは、Retriverを評価するための仕組み作りを行い、簡易的な実験とレポートを行ってみました。評価データセットの標本数が非常に小さく、全面的に信頼してよいという結果ではないため、今後は評価データセットを拡充し、複数人で精査することでバイアスを減らすとともに、より一般的な性能評価を目指せればと思います。
参考文献
[1]: Laura Carnevali, Evaluation Measures in Information Retrieval, (2023) Pinecone
[2]: Shahul Es, Jithin James, Luis Espinosa-Anke, Steven Schockaert, RAGAS: Automated Evaluation of Retrieval Augmented Generation (2023), EACL
[3]: Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Cheng Jiayang, Cunxiang Wang, Shichao Sun, Huanyu Li, Zizhao Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, Zheng Zhang, RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation (2024)
[4] Cross-Encoders, SentenceTransformers
[5], Laura Ham, Using Cross-Encoders as reranker in multistage vector search, (2022) Weaviate
[6] mblondel, mblondel/letor_metrics.py, GitHub Gist
[7] DCG, Wikipedia
アンケートを、ラクに速く。
タナカさんなら、AIがアンケートの設計から分析まで一気通貫で対応。数日かかっていた作業が数分で完了し、すぐ施策に活かせます。
無料ではじめられるので、まずはお試しください。
NEWS
新着記事

Blog
2026/7/1
アンケートで顧客満足度を把握し、製品改善のヒントを見つける

Blog
2026/6/15
ユーザーエクスペリエンスとは?UX改善に役立つアンケート活用方法を解説

Blog
2026/6/10
CSATアンケートテンプレートで顧客満足度を測定し、サービス改善につなげる方法

Blog
2026/6/10
NPSアンケートテンプレートで顧客満足度を測定し、サービス改善につなげる方法

Blog
2026/5/25
複数回答アンケートの集計方法|Excelの使い方からAI活用まで一気に解説

Blog
2026/5/14
アンケートメール・リマインドメールの例文集|回答率を上げる書き方・件名・コツ






